Speech Based Computer Games
By Stephen Davison 2/5/2001
Supervised by Steve Renals
This
report is submitted in partial fulfilment of the requirement for the degree of
Bachelor of Science with Honours in Computer Science by Stephen Davison.
All
sentences or passages quoted in this dissertation from other people’s work have
been specifically acknowledged by clear cross-referencing to author, work and
page(s). Any illustrations which are not the work of the author of this
dissertation have been used with the explicit permission of the originator and
are specifically acknowledged. I understand that failure to do this amounts to
plagiarism and will be considered grounds for failure in this dissertation and
the degree examination as a whole.
Name:
Stephen Davison
Signature:
Date:
2/5/2001
Abstract:
From investigating what speech is, and what it is commonly used for, it is proved possible to create a game that matches the interface in the case of a speech based computer game where you can command bots using speech. To do this, the multi-modal potential of speech has been realised to overcome problems that existed in various bot command systems of interface conflicts. Bots have been implemented to be asked information and given orders to interact in a certain way with the game world and it’s contents. To create the system, appropriate experiments and design methods are shown to identify potential problems with the interface and with the system which can then be considered during the design process. The project is then discussed and it is shown how improvements may be made to this project.
Acknowledgements:
Many thanks go to the following people:
·
Steve
Renals, for inspiration, support, feedback, enthusiasm and guidance.
·
Steve
Maddock, Ian Badcoe and Alan Watt for interest and feedback.
·
Simon
Marlow, Ben Askew, Graham Matthews, and my Mum for testing and additional
feedback.
·
Duncan
Watson, Andy Clark, Jack Bamford, Rob Kelly, David Meakin, Stephen Vernon, Matt
Griffin, Paul Hamer, Andrew Hardy, Carl Atta, Anthony Whiteoak, Kate Roach, and
my Dad for enthusiasm, support, and comments.
·
Douglas
Pride and many other people who have given suggestions and advice.
·
Many
other thanks go to the people whose work has been referenced in this project.
Without such work, this project would have not been possible.
Speech
Based Computer Games:
Contents:
Chapter 1: Introduction 1
Chapter 2: Literature review 2
2.1: Interface 2
2.2: Java Speech API 3
2.3: Speech based computer games for Blind People 3
2.4: Modalities 4
2.5: Human Issues 5
2.6: Technology 6
2.7: Bot control systems 8
Chapter 3: Creation of a
speech based computer game 12
3.1: Design 12
3.2: The Prototype 13
3.3: The Wizard of Oz experiments 13
3.4: Implementation 15
3.4.1: The
speech recogniser 15
3.4.2: Parsing
recognised tags 15
3.4.3: Giving
the bots information 15
3.4.4: Bot
comprehension 16
3.4.5: The
current system 16
Chapter 4: Testing 18
4.1: Speech Interface Testing 18
4.2: Grammar Testing Experiment 18
4.3: Bot Humanity Experiment 18
4.4: Interface Mode Change Experiments 19
4.5: Interface Mode Supremacy Experiment 19
4.6: Interface Acceptability Experiment 20
4.7: Results from an Interface Acceptability Experiment 20
Chapter 5: Evaluation and
Discussion 22
5.1: Relationships With Other Projects 22
5.2: Possible Improvements to This Project 23
5.3: Advanced projects 25
Chapter 6: Conclusions 26
References: 27
Appendices: 29
Chapter
1: Introduction
Even
since old science fiction films such as 2001, there has been the possibility
that one day, people will be able talk to computers to get things done. This
has now become a reality due to better technology, and it is now possible to
use speech in computer games instead of a mouse or a keyboard. This is made
difficult because of many different factors. The user might not want to talk to
a computer, because it is unusual to talk to inanimate objects. The user may be
confused why they would direct a pointer by asking it to move “Up a bit” when
it would be easier to move a mouse. There are many additional issues involved
with speech based computer games, and these tend to come out mostly when a game
is in the process of being designed. Many previous attempts to attach a speech
interface to a current game have failed because the game was not suited to the
interface. From investigating what speech is, and what it is commonly used for,
it is possible to create a game that matches the interface.
Through
examining speech in detail, many aspects of speech become apparent. It is
possible to speak and do other things at the same time, which proves the
multimodal potential of speech. It can be seen that the main use of speech is
to get things done. It is simply yet another means at our disposal to interact
with the world. To find out information and to give orders. Most of the
situations where you would want to do this involve communicating with people.
One of the main problems with current first person shooting games is that the
computer bots on your side are notoriously difficult to control. Most of the
command systems require that the interface which controls the player’s normal
actions is used to command. This makes the player unable to use normal actions
if he uses any of the commands because they will conflict with normal actions.
Because of this, the usual course of action for the player is to ignore the
commands available and to attempt to win alone. This is an ineffective system
in a team game because the players are being trained to be independent by the
ineffective interface.
Since
speech is multimodal, it is possible to use speech while playing normally. This
allows the potential for the player to command the bots while still playing
using different controls. This would solve the problems with the game and give
an opportunity for the player to use his team to the best advantage.
In
this dissertation, it is shown how speech controlled computer bots may be
created and tested with appropriate experiments and design methods. This
dissertation also looks at speech based computer games in general and how
problems with these games may be solved and why they exist.
In
chapter 2, aspects of speech based computer games such as interface,
modalities, technologies and human issues are examined. There is also an
overview of games for blind people and an examination of the current state of
bot technology in computer games. In chapter 3, the creation of speech based
computer games is shown in the various stages of design. Chapter 4 looks into
the ways in which speech based computer games may be tested and what doing
these experiments may prove. Chapter 5 evaluates the project and asks what can
be learnt from this dissertation. This chapter also discusses what the next
stage in speech based computer games may be with respect to further research
and fields of study related to this project. Finally, chapter 6 studies what
the dissertation has proved and concludes the project.
Chapter
2: Literature Review
There have been many projects which have revealed many of the potential problems that this project could have met. These range from research projects to commercial games that have been released to the average games player. Such scope is important because although there may not be a problem with the technology during research and testing, there are sometimes problems which occur because the technology is not compatible with the user.
2.1 Interface:
There
have been two similar dissertation projects in the past on speech based
computer games, and each was based on a different game. In the dissertation
that was done two years ago, Steve Lackenby [1] created a pacman style game
controlled entirely by speech. This was a large step for speech based computer
games because it highlighted the way in which different modalities of input
could be used in the wrong way. Speech was proved an unsuccessful modality for
the fast reaction speeds that a game such as pacman required. It was shown that
there was a large speech processing delay from the time the word was uttered
and the time that this was fully processed. This meant that where the aim was
to go a certain direction, by the time the words were spoken and processed, the
aim had probably changed to something else. In this and fast reaction games,
such as Quake 3 Arena [5], a delay in the interface reaction speeds creates lag
and this can be mentally disturbing for the player since the response from the system
is not the same as what the player thought the system would do.
The
pacman game also had another issue in that when the player got excited, the
quality of the speech from the player degraded. This meant that the speech
recognition did not work as well and that the interface broke down. This caused
a vicious circle in that if there was a ghost heading towards the player, the
player would get excited which meant the interface would degrade, causing more
ghosts to come after the player, causing more excitement until the player lost
a life.
One
aspect of speech based computer games raised by this scenario is that if the
speech interface is used very often, the user gets uncomfortable because it is
exhausting to speak constantly for a very long time. Even in conversation, each
person who is speaking does not speak constantly and each person is relieved by
the other in various places. If there was very little speech in the game at
all, is it really needed in the game? There is obviously a balance needed between
the amount of speech required in the game and the amount the other modalities
are used.
In
last year’s dissertation, Mark Wrangham [2] saw the link between speech and
natural language text input in text adventure games. This was a good
implementation for a speech based computer game, but it had a couple of minor
flaws. After testing the system, it was shown that the speech interface was
slower than the previous text interface. This was due to a couple of reasons.
The speed of the speech interface was slower than a normal speech interface
because of the speech processing delay. The speed of the text interface was
faster than with a normal person typing because the people who play text
adventure games are generally faster at typing because they play text adventure
games a lot and have lots of practice. Since these people played the text
adventure games a lot, they were more accustomed to using the typing interface
than a speech interface, and they felt less comfortable with the new speech
interface. The lesson learned from this dissertation was that even though
another modality may be used, it may not the best modality for the job.
The paper by Sharon Oviatt [3] explains that one of the main advantages of using multimodal systems is that the strengths and weaknesses of the interfaces may be capitalised on with one interface making up for any weaknesses in the other. This is an interesting idea for speech based computer games because it means that where previously high reaction games were not suited for the speech interface, now they could be if there was another interface that can handle the high reaction part of the game. This could lead to a game that uses a usual interface for that type of game and has a less time critical additional feature controlled by speech.
2.2 Java Speech API:
The
Java Speech API (JSAPI) programmers guide [4] is one of the most useful tools
for creating applications with speech input. It includes information about
where speech is useful in speech based applications and how to implement the
system. It is shown how feedback is one of the most important aspects of speech
applications because the user needs to know what is happening. This is because
the usual reaction of a system to something it does not understand is to do
nothing. The system needs to give pointers as to how it understood what the
user has said. This would lead to the system saying phrases such as “I don’t
understand” and phrases that sound similar may be reported on in a way that
shows the user some level of understanding. For the slightly similar phrases
“where are you?” and “who are you?” the response would show that the phrase was
understood, but for “washing” and “watching” the words may be repeated back to
the user as the task is undertaken. For potentially dangerous situations there
could be a little delay intended for the user to change their mind. This would
be appropriate if the item you were about to tell someone to “watch” or “wash”
was an electrical appliance.
There
is a point that should have been given a little more attention in the JSAPI,
and this is that the most successful speech applications are those which use
the speech interface to add a dimension to the application which was not in the
original. This is true of all interfaces and it should be made clear that if
the interface is not useful and does not add anything to the interface that is
helpful, then that interface should be dropped. One such applications could be
a speech clock that you can ask the time of using a speech interface, and the
program will then use the synthesiser to reply the time even when the clock is
displayed full screen with a bright neon display.
2.3 Speech based computer games for Blind people:
Using
the previous example of the speech operated clock, this would be useful for
blind (or partially sighted) people, even though sighted people might not
appreciate the idea fully. A conversational input with speech would be useful
for blind people, and could be an interesting field for more research. One
potential aspect being that there could be additional visual information
encoded in images so that the computer could be asked what it sees. “There is
an apple” could be a reply. When quizzed further the added information could be
as poetic and as descriptive as desired by the user. This could be broken up
into aspects of the picture so if the user was interested enough, the user
could probe the image with questions and such. This could be almost implemented
in a tag stack with the object creating a list, and each successive question
could expand the list of description tags further and further. From such
awkward visual information as “The apple is mottled red and yellow” questions
could be asked about the other aspects of the apple, and more questions could
be asked about the colour giving opportunities to ask how the colour makes
people feel and what it reminds them of. Certain tags could be linked to the
system dictionary database. The descriptions would have to be written by teams
of people who have experienced those things but cannot any more and people who
were born blind so that they would be in a position to discuss what the
descriptions should be. The descriptions would then have to be tested on a
different blind person every time until the description was perfect. This would
be so that the conversation between the designers was not required to
understand the information. Such an operating system would need to act like a
person, and the response from any system commands would need to be different to
the voice used for dictated text.
With the prospect of speech based computer games, various new games for blind people will be able to be created. Currently, computer games for blind people are available on the Internet, but the sites for these games and the gamers change quite often. Such games that exist use audio in a variety of ways. A boxing game makes different noises when punches are heading towards different parts of the body. Another game uses sound to warn of obstacles in a racing game. Some games that were not designed for blind people are compatible with a system which uses a synthesiser to convert the text to speech, and some games that are not particularly text based are able to be converted using an emulation utility. Some games that are point and click adventure games only use the mouse interface to generate the sentence which is then put through a text parser. Monkey Island [15] and Space Quest [16] are examples of these. The graphics are references to images and these images can be converted to names and then written on the screen.
Using the description system above, more interesting games could be created. It would be easy to imagine a game based on an interactive detective game. Detective stories such as what was on the radio before television. The player would play the detective, and would have to talk to everyone and piece together evidence to solve cases. In case the player forgot any of the information, there could be a sidekick to remember it who could be asked at any time. There could also be a narrator who explains what is going on as it happens, and an atmospheric partially scripted score. This would allow for similar effects like gunshots used in the original shows. The player would be able to order a taxi to visit people around the city, and the voices could be made stereotypical so it is possible to distinguish between the character traits. This game could be advanced enough to change the plot many times, as in Blade Runner [17], and many stories could be produced easily. If the voices of the actors were all synthesised perfectly, the size of the game, and the ease of modification (only creating a text script instead of real recorded audio) would be more efficient.
2.4 Modalities:
New
modalities have been introduced into computer games over many years. In the
game pong, the method used to control the bat was a dial that was turned to
move the character. This has advanced into such modalities as joystick and
mouse interfaces. It is not only the external interface that matters in current
games. Some games use sub-interfaces where different aspects in game are
controlled in different ways. Many games have different methods for controlling
different types of action in the games. Final Fantasy 7 [18] is a good example
of this as almost every sub game has a different method of control. Some games
even go further than having sub games and incorporate the same interface in the
entire game. In Zelda 64 [7], there is an instrument called an ocarina that the
player can play to perform some spells. These spells are needed to advance
through the game, and the opportunity is given for them to be learned. The
instrument plays different notes when different buttons are pressed on the
control pad as soon as ocarina play mode is activated. If the interface used to
activate spells were speech, then a play mode would not have to be activated
but there could be a possible conflict between the spells being incanted and
any other use that the speech interface had. For this to be added to a
role-playing game the spells could be made so you had to speak the incantation
for a spell before you could use it. Newer versions of the spells could be made
more complex, but the complexity would be made worthwhile because the effects
of such a spell would be far greater.
2.5 Human issues:
In
current computer games the most successful games tend to be the ones which are
most immersive. These games extend the playing experience and allow interaction
on many levels. In Half-Life [9] there are many different levels of
interaction. The first level of interaction is physical. The player is given
the opportunity to move around realistically even in environments such as
water. The second level of interaction involves objects. The objects may be
moved, used, and sometimes broken. The third level of interaction involves the
characters. The characters may succumb to the same hazards as the player and
they may be ordered around to help. The fourth level of interaction is
response. The characters are given the ability to react back to the player.
This includes feedback when the player has ordered the character in both speech
and motion. The characters are also scripted to react to each other and some
objects in some places. The characters also act to give the player information
about the state of the plot in the game. All of these levels of interaction
expand the game and involve the player more in the game world. They also
convince the character that the world is more real than they might otherwise
think. The key to this interaction involves careful scripting and creating
advanced AI in the bots. In this game, the most impressive bots are the Special
Forces characters. They have behaviours such as clustering, surrounding,
retreating, and running away from grenades. They use speech to maximum effect
and this can be seen best when they shout, “Fire in the hold!” when you throw a
grenade at a group of them. They also have other phrases such as “Go! Go! Go!”
and “I hear something!”. Such phrases add depth to the game because they make
the player more scared than if a couple of bots charged in without the speech.
The use of lip-synching in the game extends the realism of the game, and the
characters face you when they speak. To add speech control to this game would
be a good idea because the environment of the game supports speech control
since the bots already talk back to you and allow interaction on the basis of
using them by pressing a single key. It is also a simpler environment to talk
to because of the ways in which the characters talk to you.
One of the greatest problems in speech-based applications is based on the people, not the technology. Although people are generally happy to speak to one another, when speaking to a machine these people tend to feel very uncomfortable. The reason for this is that usually when you are speaking to someone you are constantly expecting a response, whether this is verbal or physical. It is very disconcerting for a person to speak to someone if they are staring something and have no response at all. A game such as Half-Life might ease this feeling by having something to talk to and humanizing it with such techniques as lip synching and having the characters turn their heads towards the player when they speak. Having a response goes some way to ease this feeling but it requires that the computer must make the first move to prove that it will respond. One factor of this problem is due to the quality of the speech used in the response. In modern games this is currently sampled beforehand but takes up a lot of space and cannot be changed very easily. Synthesised speech seems a solution to this but usually results in an artificial response with very little emotion. With ViaVoice [6] the emotion can either be bored or confused. In The JSAPI Programmers Guide [4] it is explained how there is a trade-off between speech which is easily recognisable but artificial and speech that sounds human but might not be very understandable. The speech produced sounds similar to the voice over on the Radiohead song “Fitter, Happier” [19], and is artificial. Although using synthesised speech might have an adverse reaction in game, it is suitable for low budget testing. At the end of testing, the synthesised speech sentences could be replaced by audio samples that add to the theme of the game.
In
Half-life [9], the manner in which the characters talk back to the player is
implemented by having a group of samples for each type of response. The more
samples that are in these groups, the more realistic the response will seem.
This doesn’t just mean that there must be numerous samples that mean the same
thing. It also means that there could be a lot of samples which say the same
thing but are said in a slightly different way. When people speak, there are a
number of different factors which alter the way the speech is produced. This
means that speech is rarely repeated exactly the same every time. Even two
phrases spoken in the same conditions can have different fluctuations. Because
of the attributes of speech, the audio quality may be set almost as low as
telephone quality. This would make it possible to store lots of samples. When
recording these samples even the previous takes of recording a sample correctly
may be used to advance the effect. In Half-Life, the main shortcoming of the
speech response system was that all of a certain class of people used the same
samples. This was disconcerting because in some cases the samples were created
by different actors. The characters of the classes also had different faces,
which gives all of the characters a minor personality crisis.
2.6 Technology:
In
speech based computer games technology plays a large role and there are a lot
of features that have been created to deal with certain problems. Some problems
have not yet been fixed in the field of speech based computer games, however.
For example, although the grammar in a game might be quite small and the set of
words that it is possible for the game to understand might be quite small,
training ViaVoice [6] for each separate user can take about half an hour for
each user. For a user of a game to invest such a large amount of time training
a recogniser to recognise words that the user will probably not be using is
unfair. The training of the data is specifically centred on a much larger set
of words and this means that there is a lot of redundancy. The game “Hey you
Pikachu!” [10] manages to avoid training altogether. Using a voice recognition
unit between the controller port and the microphone, there are a couple of ways
in which this requires less computation. The first is that it is designed for
children, and children tend to have similar voice patterns before they mature.
The second is that the set of possible words is very low. In the Japanese
version of the game “Pikachu genki dechu” it was made easier to create because
the Japanese language uses fewer phonemes than English. This gave the creators
a head start in creating a speech based computer game because of the reduced
complexity. This may have helped the design of the English version if the
English words were broken down into Japanese phonemes such as Pi-Ka-Chu. One
way to deal with the recognition is to give it to the user slowly. This would
be a type of training level where each part of the control would slowly build
up. In this way the speech recogniser learns at the same pace at which the user
is learning what to say.
Another
aspect of speech based computer games is that there is a large amount of
processing power required to recognise speech. Although processing power is
increasing rapidly, there is still a significant resource drain. When 3D
computer games were getting more complex, companies such as 3dfx created
hardware 3d accelerators so the processor could be used for other things.
Speech recognition cards could be created to recognise phonemes from speech and
then process this into relevant text output. These would help performance
issues and they would have the advantage of being interchangeable since the
input and the output would remain the same.
One
important issue with speech based computer games is that the user will be
expecting full surround sound with a large subwoofer, but will also be
expecting the recogniser to process speech in the same noisy conditions. This
is a problem for the microphones, and although noise-cancelling microphones
work, they need improvement. At the moment, noise-cancelling microphones have
two microphones, one facing towards the mouth and one facing away from the
mouth. The signal facing away from the mouth is assumed to be background noise,
and is removed from the signal facing towards the mouth. This is done before
the signal goes into the computer. If there were anomalies introduced into the
signal at a pitch that only the computer could hear, the computer could have a
backlog of produced audio signal and it would know exactly what part of the
backlog interferes with the incoming speech. The exact same parts of the signal
could then be removed. Another possibility would be for the computer to produce
sound that has gaps in it. These gaps would not be audible to the user but the
computer would be able to remove the parts of the speech signal that was
destroyed with its sound and only use the rest of the signal to process the
speech.
The
JSAPI [4] supports multiple grammars. This would be useful in an adventure game
where the player goes into shops and fights battles, but not at the same time.
There could be a shop grammar and a fight grammar, and the smaller separate
grammars could reduce the speech processing delay. Unfortunately, changing
grammars requires restarting the speech recogniser, which can sometimes take a
long time. It would be nice if all of the grammars could be loaded when the
recogniser engine was created and then switched swiftly.
Although
I will be using a grammar system for my speech recogniser there are alternate
modes available. There is a dictation mode which is able to convert what you
are saying into text. This is the standard method of speech recognition. The
power of this method can be increased by using speech grammars. These constrict
the possible speech to a certain form and make it easier for the recogniser to
decide what was said. Anything that is not recognised by the grammar is
rejected as a result.
Some of the programs that are designed to pass the Turing test [20] are based on statistical key word detection. For example, a sentence with the word “football” in it might result in the system response of “I like football but I don’t watch it.”. Such a system could be effective in speech based computer games to increase the amount of things that the user can say to the system. If this idea was used to enhance the dictation mode, it would be possible for the computer to realise that the player had said the word “Help” and would make the computer wonder who to help and then search words to see who was mentioned. This is a powerful idea but can be made to break down very easily unless the system was able to understand negatives such as “Don’t help that player.”.
Another
direction that speech based computer games can take is to have conversations
between the player and the characters in the game. A game called seaman allows
you to do this. The vocabulary for this game is quite complex but it is all
processed in a statistical key word detection manner. The different responses
to questions asked by the character result in different scripted responses by
the character. The entire game is scripted in this way with every conversation
having a different result. Some information is stored by the game for later
such as when your birthday is. Most of the conversations start with questions
such as ‘have you?’, ‘did you?’, ‘do you?’ which mostly have yes or no replies.
Some of the questions in mid conversation have other possible replies which are
mostly all expected by the vocabulary.
2.7 Bot control systems:
There
are many reasons why this project is based on controlling bots via a speech
interface. These range from the current state of bot control to be inefficient
through to examples where bot control via speech is a realistic idea.
In
Quake 3 Arena [5], the bots have the power to do their job quite well.
Unfortunately, this power is not effectively controlled and so the idea fails.
There are two different interfaces that may be used but each uses part of the
usual interface of the game. The menu system may use the mouse or the keyboard.
The menu is two layer which means that it does not take very long to select the
commands but the fluidity of the game is compromised since the game pauses
while selecting commands. The bots have a tendency to forget what you had just
ordered them to do and go and do something completely different. This is
frustrating for the user because it means the system does not have an expected
output and it also means that the bots are not controlled. There are about 8
commands that it is possible to use, and the commands are lacking in power.
There was one time where the bot was ordered to take up a camping position next
to the rail gun so the bot could snipe people. Unfortunately, the bot stood
about 2 feet away from the rail gun and used a machine gun instead. There were
also times were the bots needed health or the quad damage but this command
system was not powerful enough to order them to get those things or even to run
away.
The other interface that may be used is a natural language command line interface which uses the keyboard. While commanding in this mode, the player is in a chat mode and can not defend themselves. There are a large amount of commands that may be used in this mode which may involve interacting with other players and various objects in the arena. There are also various roles the bot may be asked to perform such as camping, patrolling, roaming, and covering. All the possible objects may also be used as positional references such as “<botname> patrol from <loc/obj> to <loc/obj>”.
This
natural language interface is a similar type of interface to which will be used
in this project. The aim is that this project will use speech so the player can
carry on playing and avoiding threats while ordering bots around.
In
Kingpin [8], the control of the bots allowed you to put your bot in roaming
mode, bodyguard mode and standby mode. The bot had a tendency to run into a
group of enemies and get itself killed, which usually got you killed as well
since the enemies would all run out together. There were also instances were
the bots would get in the way of the door you needed to go through and would
not leave so you had to kill it. There was also a simple conversation mode that
allowed you to talk to other characters depending on whether you wanted a
positive conversation or a negative conversation and some characters would also
get angry if you had your gun out. This was one of the factors which made the
characters turn on your bot and then they would then turn on you. The player
has a voice implemented which is unusual in some games since it is usually best
that the player does not know what voice they have to make the player feel like
they are playing, rather than that they are controlling someone else that is
playing the game. The amount of phrases that this voice can say is quite low so
it would be easy for this to be implemented in a speech input interface. The
style of speech involved a lot of swearing, so this might confuse the
recogniser and the player. If the speech interface was implemented in a
statistical key word manner rather than a grammar form, this could be
implemented such that swearwords indicate a negative conversation and words
such as “information” and “what’s happening?” indicate a more constructive
positive conversation. The sum of negative and constructive words could
influence the emotion of the characters and change the type of game entirely.
The
main justification for having bots controlled by speech in computer games is
the game “Hey, you, Pikachu!” [10]. In this game, the user is able to talk to
Pikachu in a variety of ways to get things done. The game gives the impression
that Pikachu is your pet. This game has been released in both Japan and America
so it proves that speech based computer games are a marketable product as long
as the game comes with the voice recognition capabilities needed. If the user
had to buy an expensive version of ViaVoice or Dragon Naturally Speaking to
play a single game, the price of the game would be far too expensive and the
user would purchase a cheaper game. Releasing speech based computer games would
only work if there were a large enough selection of speech based computer
games. If these games came with basic speech recognition software and there was
the opportunity to upgrade the capabilities with a commercial speech
recognition package then the games might have more commercial success.
This
game was designed in mind for children and this can be seen in a variety of
ways. The first is that the grammar is taught to the player gradually and the
game has a gradual learning curve. The second is that the game is broken down
into many sections so there is a place to pause every so often which is useful
because children can sometimes have short attentions spans. The third is that
there is a constant reminder about the words you can say in information that
pops up sometimes such as “Pikachu has a Strawberry. You can ask him ‘how’s it
taste?’.”. Possibly the most interesting part of Pikachu’s behaviour is the
emotions that Pikachu seems to possess. For example, if the player tells
Pikachu “Your so cute!” Pikachu will blush and smile. If Pikachu wants to show
the player something he points to it, and if the player does not interact with
Pikachu then he falls asleep.
The
game uses the speech interface to do a variety of things in many sub-games. In
one the player has to encourage Pikachu to catch a fish and in another the
player has to get ingredients for some soup. The game requires that the speech
interface is used in the game to complete it but it is more of a pet simulator
than a game that can be completed. The game also has quite a realistic world in
which to interact with Pikachu. This results in the player feeling that having
a two-foot tall yellow mouse that can electrocute things is normal.
The
game’s flaws are all based on the speech interface. A lot of the time Pikachu
does not understand what you say or does not understand the wording, and in
some of the games this can be a setback. For example, in the ingredients game
you tell Pikachu what he needs from a notebook with pictures in. He will then
run and pick up a vegetable. If you want Pikachu to send the ingredient then
you say “sure”. Saying yes tends to make him eat the object rather than sending
it. Sometimes the speech recogniser fails and he drops the vegetable you need
to send and runs off. When this happens it can be frustrating for the player
and the reaction is to use another interface rather than the speech interface.
The player then attempts to find the ingredient needed and give it to Pikachu
personally. This is a breakdown of the interface and a problem because the
player is more reluctant to interact with Pikachu. This may have been because
the player used to test the game was older than what the voice recognition unit
required but the feeling that Pikachu understands you is the best emotion felt
while playing and is possibly the most important in this kind of game to get
right. The reason why it is such a good feeling is because it bridges the gap
between the fantasy game world and the real world. The fact that such a
character can understand you by itself is almost too incredible to understand
because it is pure science fiction.
Apart
from the Pikachu game, the next closest project to this dissertation is
“’Situated AI’ in Video Games: Integrating NLP, Path Planning and 3D Animation”
[12]. This project focuses on controlling an avatar in a computer game via
speech. To do this, many different techniques needed to be developed to support
the speech interface such as path planning. The environment that this project
uses is an emulated DOOM environment. This allows the language to be
descriptive since the objects in the doom environment may be interacted with
and used in many ways.
The
fact that the world is semi 3D is proved not to differ from 2D because the
avatar always walks on the surface. This is an interesting result because it
means that bots developed for a 2D world may be easily converted to bots suited
for a 3D world where they walk on the surface. Any additional programming would
be related to the change of the targeting system to target an enemy vertically
as well as the normal method of targeting.
The
method in which this project gathers the grammar that may be spoken in the game
is interesting but may have some flaws. In speech based computer games the game
is required to expect what will be said and then process how this will be dealt
with. What the game expects the player to say may be broken down into a grammar
to aid processing for the speech recogniser. To create an accurate grammar from
scratch is a difficult process but this project uses DOOM spoilers to get the
sample grammar. The DOOM spoilers are designed to guide a player through the
game using such descriptive commands as “Kill the cyberdemon with the
chaingun.”. The potential flaw in doing this is based on the fact that people
treat people and machines differently so the grammar may be ineffective for a
player to control a machine. The ambiguity is also different because when you
talk to a person, it is expected that the person knows the ambiguities of the
language. When you talk to a machine you are constantly probing it to find out
just how much ambiguity it understands. This is a similar concept as if you
were to speak to a foreign person since you would not know just how adept this
person was at your language. It might be the case that this is an attitude
based on feedback from who or what was being talked to. The language that
people use when talking to machines and people is also different because it is
made clear that when talking to a machine you order it to do things in a
superior manner whereas when talking to a person it is considered rude to do
this.
The
method in which the player can interact with the avatar is only on one level
and the player is not able to support the avatar. This is not the aim of this
dissertation at all since this dissertation is based on controlling bots using
a speech interface and allowing the player to do this at the same time as doing
other things in a multimodal manner. This project differs from this
dissertation in that the avatar is not your teammate designed to help you; it
is your only means of interacting with the world. In this dissertation the bots
can do their own thing but can also be ordered to do other things so they are
not totally reliant on the player. In the game in this dissertation the player
will need to use the bots effectively to make the game easier.
In
the game that will be designed in this dissertation the language will be much
different since the bot plays the game as well as the person. This would result
in not telling the bots specifically how to play the game, but in telling them
to play the game in a different manner. Such commands would include asking the
bot for help and asking the bot for support in various ways with certain
challenges. This is a different level of complexity of commands. The commands
depend on each other in a structured fashion with the basic commands such as
“go forward” acting like the building blocks of other commands. In the project
the commands infer few things related to the command but in the game created in
this dissertation, many things are inferred such as what needs to happen before
the orders are carried out.
This
project deals with the various techniques involved with path planning more in
depth than in this dissertation. This is because this dissertation is focussed
mainly on the creation of speech based computer games while the project focuses
more on issues related to situated AI.
Chapter
3: Creation of a Speech based Computer Game
The
creation of speech based computer games requires 4 stages, which are design,
prototyping, grammar retrieval, implementation and testing. These are applied
in a project lifecycle that will be shown to be suited to the creation of
speech based computer games.
3.1 Design:
The
design of a speech based computer game requires that the game being designed is
specifically suited for speech. Technological and human issues need to be
considered thoroughly since the game needs to be feasible and needs to be
suited to the players. There are three different types of speech interface that
may be used and the benefits and drawbacks may be summed up in table 1:
|
Interface |
Benefits |
Drawbacks |
What
it may be used for. |
|
Grammar
based Speech input. |
May
be parsed in a series of tags. This allows the important parts of the
sentence to be filtered out. Can
improve recognition accuracy. |
All
possibilities of the commands may have to be allowed for, creating a complex
grammar. Grammar
creation is difficult. |
Command
based system where the commands are known. |
|
Dictation
style speech input. |
Converts
natural language to text. Allows
words not expected to be dealt with in a more user-friendly manner. |
Natural
text is more difficult to parse than tag text. Dictation
accuracy might fail in mid sentence causing entire sentence to be
miss-parsed. |
Could
be used where existing method of parsing natural language exists. Natural
language conversations between characters. |
|
Dictation
style speech input parsed with key word recognition as in a program
attempting to pass the Turing test. |
Is
able to respond to most sentences. Gives
an impression that the program knows more than it does. |
Might
respond incorrectly to some sentences. Needs
to understand negatives such as “Don’t attack me.”. |
An
interface to a character that may respond and hold a conversation with the
player. |
Table 1. Benefits and Drawbacks of different Speech Interfaces.
For
this project, the manner of speech input which made the most sense was the
grammar based input to allow bots to be given accurate orders. With the
intention of finding if speech control would help in team games, a team game
needed to be created. A simple game of team deathmatch in a 2D arena was a good
choice because it requires that players act co-operatively to score points.
This game was created in a prototype form to discover the grammar for the game.
3.2 The Prototype:
The
prototype was made in such a way to discover if the environmental changes would
show in the grammar. Walls were added to give some cover and they were given
different colours in an experiment to find out whether the players would use
the colour as a positional reference. The bots were made to roam around and
were given different letters to distinguish each bot and act like another
reference. In order to add more interaction than simply running around in a 2D
arena, it was made possible to shoot the other bots. At this stage the bots
were not given the capabilities to fight back, which may have been a mistake
since certain commands related to dodging and running away were not fully
examined.
3.3 The Wizard of Oz Experiments:
In
order to discover the grammar for the game, it was possible to use an
experiment known as a Wizard of Oz experiment. In “The Wonderful Wizard of Oz”
[21], it was seen that there was no real wizard, only an ordinary man sitting
behind the screen pressing switches. In a Wizard of Oz experiment [13], the
user of the system is given the impression that an amazing interface is
working, where in fact there is an ordinary person sitting behind the curtain
pulling switches giving the illusion that the interface is amazing and working
perfectly. These experiments show what the game would be like for the player if
the game was accurately implemented. In this environment, the user will act
like the interface exists so it can be used to find out what types of grammar
need to be implemented to support the user when the game is fully implemented.
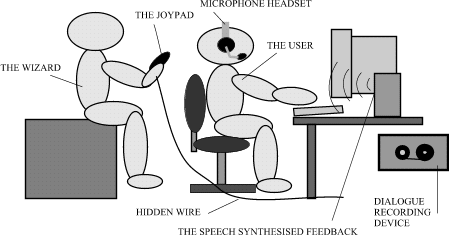
Figure 1: A Diagram of the Wizard of Oz Experiment.
In
figure 1, it is possible to see how the user was given the impression that the
interface was perfect. If the user could see the joypad, the user would have
realised what was happening and would have changed their grammar. The
fictitious interface would break down and the user would have a different
attitude. To have some basis of interaction, the player was given movement
controls and a fake bot on the player’s team was created for the player to
command, but in reality this was controlled by a joystick interface created by Satoshi
Konno [14]. This joystick was hidden from the player so the player could be
lead to the conclusion that the character on his side was real. Using the IBM
Java Speech API implementation [4], a response system for the fictitious bot
was created using the speech synthesiser. This was controlled by the joystick
and was made more interesting by the fact that there were four different
responses for each of the three categories of response. These categories were a
positive response, a negative response, and a confused response. The player was
told the controls and told to tell the fake player to do things. The player was
given a trial run to practice the system and then the next test was recorded
with both the speech input and output together. To get a picture of the
possible users, tests were run using players that were adept at using computers
and those which were only passive users.
The
dialogues that were recorded were then analysed to find common constructs and
redundancies in the speech. These led to the creation of the first grammar.
This grammar was then examined for ambiguities and manually changed
accordingly. Through examining the dialogues it became clear that the users
would create their own grammar naturally, with the successes and the failures of
what happened in the game world deciding whether the user used the grammar
construct. Other shortcomings in the grammar such as the possibility of having
players run or walk could be identified. In this way it can be seen that a
project lifecycle of creating successive prototypes and using a Wizard of Oz
experiment to find where the prototype may be advanced will allow the game to
develop in a controlled manner. This will result in a set prototype for the
game to follow and a set grammar to be implemented.
The
grammar is not the only part of the experiment that yields information since
when asked about the experiment and what the user thought of the game, the user
claimed that his assistant did not respond to ‘Player at 2 o’clock’ as it
should have done. This was because even for the human wizard, this phrase is
quite ambiguous and confusing.
Such
various meanings could have been:
·
Look
at the player at your 2 o’clock.
·
Look
at the player at my 2 o’clock.
·
Kill
the player at 2 o’clock.
·
Run
away from the player at 2 o’clock.
The
user’s intent was to kill the player which was at 2 o’clock, but if there were
more players it could have also meant “Help is arriving in the form of the
Player at 2 o’clock”. This kind of confusion could be bad because the reaction
implemented could have been to kill that player, which may not always be the
desired effect.
There
were also instances where the user would get annoyed because the wizard was not
perfect and would perform certain commands differently. Overall, it was the response
system that annoyed the users the most because some user commands were
performed and no feedback was given to tell the user what the assistant was
doing. Without feedback the user loses the feeling of being in control and this
causes the users enjoyment of the game to fall rapidly. This would escalate
because the anger makes the user stress words in ways that the speech interface
couldn’t understand which would then make the user angrier.
From
the dialogue from the first test, it is interesting to note all of the sounds
of non-speech such as laughs, sighs, and clicks of disapproval. These noises
can cause problems with a dictation recogniser, one such example is that if you
laugh into the microphone while using ViaVoice, nonsensical sentences are produced
such as ‘No in the no vote no hope Norway in the 86’. Another example is that
sighs have a tendency to be recognised as the word ‘bye’.
3.4 Implementation:
When
the cycle of prototype and grammar creation is finalised, the speech grammar
needed to be implemented. This involves creating a recogniser to understand the
grammar, parsing the list of tags returned, sending the appropriate information
to the bots, and then making the bots so they do what they have been told to.
3.4.1 The speech recogniser:
The
Java Speech API allows you to create a recogniser based on a grammar that will
run a resultAccepted() event when a result is accepted. This gives an event in
a similar way to a mouseClicked() event. This event has the information
regarding the last accepted phrase spoken that exists in the grammar. This may
be returned as text, or it may be returned in recognised tag form. The tags are
applied to key words such as “chase” and “kill” in the grammar and are returned
in a sentence of tags. In the game grammar, such an example would be “player 2
find player 1”. In a tag phrase, this is perceived as “2 orderedto locate 1”.
The purpose of converting into tag form is to remove redundant speech from the
phrase to make the phrase more easily parsable. Similar words may also be given
the same tag. For the chasing example, this may be described in the grammar as:
(hunt
| locate | chase | find) {locate};
This
means that all of the words on the left may be used interchangeably in the
grammar to give the tag result of ‘locate’. The Java Speech Grammar Format is
used to write the grammar. When the recogniser is given the grammar, it
processes all eventualities that may be accepted by that grammar. An input that
is similar to some of these possibilities means that the possibilities are
compared and given a confidence score by the recogniser. If this score is too
low, the recogniser will not accept the result. There is a method given in the
Java Speech API to change the cut-off for the confidence but having the cut off
set too low might result in phrases that are not allowed by the grammar to be
recognised. With the cut-off set too high, the risk is that the recogniser does
not have the confidence to claim that anything is recognised.
3.4.2 Parsing recognised tags:
Parsing
of the recognised tags is made possible by finding the main key words such as
verbs. Once the verbs are discovered, the objects related to those words can be
found. For example for the phrase “2 orderedto locate 1”, checking the second
tag in the phase and the last for the occurrence of ‘orderedto’ will find out
if anyone has been ordered to do this command. If so, the information about who
is ordered may be taken off to allow parsing of the rest of the tag sequence.
Further processing is required to discover that ‘locate’ is the key word in
“locate 1”. From knowing that it is a ‘locate’ verb, there is now a question of
what is being located which allows the discovery that player 1 is to be
located. The bot ‘2’ now needs to be informed that has to ‘locate’ and its
target is ‘1’.
Such
parsing of the tag sequence is a structure of if statements that consider what
the first or the second tag in the sequence is.
3.4.3 Giving the bots information:
The
manner in which this information is given to the bots is by a couple of
variables. The bot is told what its current mission is in the form of a string
and it is told who its target is. This is sufficient to deal with a small
amount of commands since the bot does not have to consider any complex commands
that involve more than one player. Any other information needed for the bot to
complete its mission is in the game world, and the bot has access to that
information.
3.4.4 Bot comprehension:
Most
of the commands in the game are based on going somewhere to do something. Because
of this, the AI needs to include how to get to a specific place and how to do
the things you are supposed to when you get there. To get to where they need to
be the bots have been programmed so that they go forward until they hit
something and then they turn round a random amount until they can move again.
As soon as the bots can see the target, they turn until the target is in front
of them and then move forward.
The
current mission string which gives the bots information about what they are
supposed to do can be used by the bot to switch it’s own behaviour. This allows
certain missions to end themselves under certain conditions. For example, in
the “come” mission, when the bot is a certain distance away from the player,
the bot ends its current mission. Acceptance of missions has been added by
changing the state of the mission internally. The acceptance state is a state
which the speech recogniser forces the bot into. This state activates the
speech synthesiser to give the player information about the acceptance. The
state is then changed again into an active state that may complete under
certain conditions or may be changed in mid mission.
3.4.5 The current system:
The
current player controlled bots are capable of performing the following orders
which may be summarised in table 2, however, all the orders must be directed at
a bot for it to work.
|
Questions: |
What
this does: |
|
What
are you doing? Where
are you going? Who
are you chasing? Where
are you? How
are you? How
much health do you have? What
is the score? |
Replies
what the bot is doing. Replies
where the bot is going. Replies
who the target of the bot is. Replies
where the bot is. Replies
how the bot is informally. Replies
how much health . Replies
what the score is. |
|
Orders: |
|
|
locate
player x avoid
player x attack
player x help
player x go
to x wall come
here patrol stop continue |
Bot
finds player x. Bot
avoids player x. Bot
finds and attacks player x. Bot
finds player x. Bot
Heads towards the centre of the wall. Bot
finds player x. Bot
wanders around. Bot
stops what it is doing. Bot
continues what it was previously doing. |
Table 2. Possible bot orders.
The
questions make it possible to allow the player to ask the bot various things.
This increases the possible interaction between the player and the bot and
creates a type of relationship between the two. The way in which the questions
have been implemented is that they temporarily change the mission and then
change it back again. This gives the illusion that the mission continues as
normal. One flaw in the system is that if a bot is related to the stop and
continue feature. It is possible for a bot to be commanded to do something,
then commanded to stop, then asked a question which clears the previous mission
buffer, and so if the bot was then ordered to continue it would not know what
mission to continue.
The
bots have been given a system to vary the responses to the orders it has
received. This avoids too much repetition of each reply which would soon bore
the user. The other manner in which the responses may be designed is that they
might include some feedback as to what the user actually said. There is a trade
off between the amount of varied responses and the feedback that these
responses may return. It was simpler for the system to ignore the feedback
related to the order because this will become apparent by the action which the
bot takes in most cases. As a backup, it is also possible to ask the players
what they are doing and who their target is if the player is unsure if the
command was understood properly.
The
bots has been given their own instincts which tell them to attempt to kill an
enemy if it threatens them by moving too close. This allows the bots on the
player’s team to act sensibly. The player does not want the bots to go off and
kill the first player they see because this would mean the bots were virtually
uncontrollable. The threat system means that the bots will be well behaved, but
they will be able to make their own decisions under pressure. The threat system
could be changed to be activated when the player was not as close to the enemy
or only when the bot was fired upon.
The
enemy bots are designed to wander around and to kill the closest player of the
opposite team if one can be seen. Giving these bots a command that would work on
the other bots results in the response “I don’t take orders from you!”. These
bots are designed to avoid the closest player of the opposite team when they
are low on health but this behaviour is rarely used since most hostile
encounters between bots results in one of the bots being killed.
The
search algorithm that all the bots have is quite simple. If the bots can see
the target, the bots turn to face the target. If the target is directly in
front of the bot, the bot moves forward. One problem with this algorithm
becomes apparent when the bot sees the target when going round a corner. The
reaction of the bot is to head straight towards the target but this involves
getting caught on the corner. As soon as the bot is not caught, it can see the
target so it attempts to move forward but ends up getting caught on the wall
again. A solution to this problem would be to create a method to tell if the
bot can move towards the target successfully and using this as the condition to
start homing in on the target instead.
The
method of turning to face the target before moving towards it is also quite
artificial. A more natural method would involve moving forward while changing
course while the bot was on the way to the target as in human behaviour.
However, this is better than the keyboard control that the users have access
to. With the current keyboard interface, only one key may be pressed at a time.
The bots should use the original method since it is more like the restricted
movement capabilities of the player.
Chapter
4: Testing
Testing may be carried out using a variety of experiments to find out different information about the system. Some experiments may be performed to examine if the speech interface is effective and intuitive, while other experiments may be performed to examine if the speech interface is the best interface to use in that situation.
4.1 Speech interface testing:
To
test the speech interface, it is possible to perform an experiment to find;
efficiency, amount of bot orders and the duration spent giving orders. The
efficiency is the ratio of points between the players’ team and the enemy team.
This will give an indication of how useful the interface is to the user. The
amount of bot orders will show how much the player wants to use the interface
and will be an indication of satisfaction with the interface. If the player
likes the interface more it will be used more. The duration spent giving orders
will show how difficult the interface is to use when compared with the amount
of bot orders. If the amount of bot orders is low and the time spent giving
orders is high, the reason will be because the interface is hard to use. The
experiment could be performed over a set time with users who had a similar
knowledge of the system.
4.2 Grammar testing experiment:
The
grammar may be tested to see if it is intuitive by another type of Wizard of Oz
experiment. Since the users that performed the Wizard of Oz experiments used
similar grammar without prior knowledge of the system, the grammar should be
the same as the grammar used by a user new to the system. To find out if this
is the case, another set Wizard of Oz experiments performed with the speech
interface in place should show the effectiveness of the grammar. The setup
would be the same as in the previous Wizard of Oz experiment except the wizard
would be replaced by the bot and the speech interface. The dialogue would then
be examined to find the effectiveness of the grammar.
In
the previous Wizard of Oz experiment, there was a response to tell the user
that the artificial bot did not understand. In the game this feature does not
exist and in its place there is only silence. This should have a negative
effect on the user and this would show in the dialogue.
4.3 Bot humanity experiment:
The
humanity of the bot has a large effect on whether the player accepts the bot
and wants to talk to it. These are the properties that make the player think
that the bot is like the player such as response times, movement style, style
of task completion, and ability of basic problem solving. To find out if the
bot is human enough for the player, an experiment similar to the Turing Test
[20] may be performed. In the Turing Test, the aim is for the computer program
to fool people into thinking it is human. A similar experiment could be
performed using the joystick interface designed for the Wizard of Oz
experiments. The aim of the experiment would then be to see if the player could
tell which times a human player was used and which times a bot player was used.
There could even be experiments where the player determines which was the
artificial human bot out of a group of bots that were being controlled. The
percentage of times the player was guessed incorrectly could stand as the
confidence rating of humanity for the bot. There is a decision to be made of
whether to run the tests on different people or not. If the same person was
used over and over again, this person may become experienced at spotting the
factors that can give the bot away.
4.4 Interface mode change experiments:
Interface
mode change experiments can be performed to prove the worth of the speech
interface and to compare it with other methods of controlling bots in team
games. The interface mode change experiment involves replacing the speech
interface with another method of controlling bots in the game and performing a
similar experiment used in the speech interface testing experiment. The methods
that will be compared are the speech interface, a switchboard interface where
every key is a command, and a menu selection interface as in Quake 3 Arena [5].
The switchboard interface will have a separate key for every command, and
another two keys to alternate the commanded player and the target object /
player. The menu selection interface will need to be controlled with the keyboard
instead of the mouse so it can be seen how having the bot control in the same
mode as other controls effects the bot control interface.
There
will be two sets of experiments carried out. There will be one set where the
game continues as you attempt to find the command, and there will be another
set that pauses the game so you can select the command. This will allow
comparisons of the success of the two styles of selecting orders. Ideally,
these experiments would show that speech is a much better interface for
selecting commands in real time, but when pausing to use the interface other
methods will be better. For team deathmatch with a single player, it is
possible to pause the game every time new orders need to be given. If two
players were combating each other with a different set of bots each, the other
player pausing the game at random intervals would annoy the user. The action
needs to be thick and fast and play should ideally be uninterrupted in such a
game.
The
users that this experiment will be performed with have a brief tutorial on how
to use each interface; this will make each interface equal. The speech
processing delay is an unavoidable condition of the speech interface and will
exist in the game as well as the testing experiments. This would mean that the
speech interface was not treated as well as the potential of perfect speech
recognition.
4.5 Interface mode supremacy experiment:
In
Sharon Oviatt’s paper, “10 Myths of Multimodal Interaction” [3], she says that
the best interface for the user will automatically be adapted for use by the
user. For example, some users using a program may use the menu at the top of
the screen while other users adapt to use a keyboard shortcut such as holding
down the control key and pressing another key. It would be possible to give the
opportunity for the user to use all of the possible interfaces and find out
which interface was finally preferred by the user. This experiment would be a
brute-force method of finding which interface was preferred but it would be a
little short of interesting comparisons of the various interfaces. There would
also be less scope for examining little details in the results that would show
a complete story about each interface.
4.6 Interface acceptability experiment:
In section 4.1, the amount of bot orders is seen to be an interesting metric. This could also be used to test the addictive behaviour of the user. To do this, the amount of orders given to a bot over a certain amount of time may be found. The amount of bot orders every minute could be examined for ten minutes. This would show the trend of use of the interface. If this drops over time, the user has lost interest in using the interface, and if this stays fairly level, the user has accepted the interface. An increase in the use could be a result of the users learning curve.
4.7 Results from an interface acceptability
experiment:
The
interface acceptability experiment was performed on a single user twice. In the
first experiment, the user had very little knowledge of what the grammar was
and what the user could say. In the second experiment, the user had been given
a tutorial on the different things the user could say to the bots.
The
orders given to the bots were classified into those accepted by the system and
those rejected by the system. The user was not specifically trained for use
with the speech recogniser, so this could affect the results quite a lot
because the user has a higher sentence rejection rate. The results of the two
experiments can be summarised in two graphs:
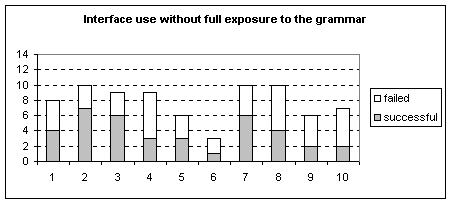
Graph 1: The interface use before full exposure to the grammar.
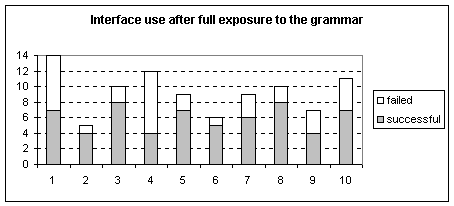
Graph 2: The interface use after full exposure to the grammar.
|
|
Total Attempts |
Percentage successful: |
Percentage failed: |
|
Partial
Exposure |
78 |
48.7 |
51.3 |
|
Full
Exposure |
93 |
64.5 |
35.5 |
Table 3: Critical Statistics of the interface use before and after full exposure to the grammar.
Graphs
1 and 2 and Table 3 show differences of interface use between a user that
doesn’t know the grammar and one that does. The two things which can be seen as
a result of this experiment are that full exposure to the grammar is much
better than minimal exposure since not only is the player’s confidence higher,
as seen by a larger amount of attempts, but the failure rate is also lower.
It
can be seen by looking at the graphs that in some minutes of the experiment,
the user had met a difficulty in communicating with the bot since there is a
larger failure rate. This happens in a larger amount in the case of the
experiment with full exposure but this can be explained by the fact that in the
first minute, the user was attempting to command all of the bots at once
unsuccessfully and in the fourth minute, the user had met with a difficulty of
the bot ‘Player 2’ not reacting to anything. Since these two problems were
unavoidable during the experiment and did not occur during the first
experiment, the user was told the cause of the problem and the solution during
the experiment.
It
can be seen in the graphs that the amount the user uses the interface
fluctuates very rapidly. This is because the user’s reaction to the speech
interface changes quite rapidly. It can also be seen that when the user has had
a lot of commands failed the next minute is usually not as command intensive.
Alternately, with a large amount of success in one minute, the successive
minute has a lot of command attempts.
There
were more effects that were possible to see during the experiments. When asked
about the experiment, the user responded with some interesting comments. The
user claimed that there were not enough commands, the bots were too slow to
respond and react after a command, and the game was a little too intense.
The
fact that there were not enough commands is always mentioned when considering
almost any natural language game since natural language might as well be
infinite if it were all to be processed, though in this case, it means that
there should have been more Wizard of Oz experiments performed. It would be
possible to merge the current bot with the Joystick control from the Wizard of
Oz experiments. The ‘Wizard’ would be able to turn off the bot and perform
additional tasks that the bot could not. This would enhance the Wizard of Oz
experiments to work even after the usual testing phase.
The
fact that the bots were too slow to react and respond is an issue related to
the capabilities of the recogniser and the speech processing delay. It is
interesting to note that since the game was so fast and the control system was
so slow to respond, the user changed their mode of speech to suit the interface
by speaking faster. The fact that the action was so intense also means that it
might be better to slow the game down and lower the action content of the game
while raising the strategic element. This result was also seen in the
dissertation from two years ago by Steve Lackenby [1] and was one of the
factors that influenced the design of this game. If this was a commercial game,
it would be a good idea for the speed of the game to be influenced by the skill
level or for the speed to be directly controlled by the user based on the users
personal preference.
An
unexpected result of the experiment was that the test user began showing
symptoms of losing their voice after 20 minutes of testing. This is a problem
since not only may the user’s enjoyment be reduced, but it also shows the
possibility that an intense speech interface may cause medical problems. This
is reason enough for future applications of speech based computer games to be
less speech intensive.
Chapter
5: Evaluation and Discussion
This
project has successfully shown how a speech based computer game may be made and
how tests may be used to aid development, from design to testing.
Without
the support of results from the experiments designed to evaluate speech based
computer games it is not possible to say if the speech interface used in this
game has solved the problems associated with bot control interfaces, however,
through playing the game, it can be seen that the speech interface is a useful
interface for bot control.
The
fact that the game has been designed to need the speech interface has meant
that the players are forced to use it while playing the game instead of using
other methods. This has been shown by the interface acceptability experiment to
have both good and bad points. The good being that the user is forced to adapt
to the interface by the influences of enjoyment and the desire to win. The bad
being that such adaptation may come at other costs such as lowered ability of the
recogniser to recognise the speech because it is too fast, and the possible
medical implications of speaking too much. The possible medical implications of
speaking too much may be found from various sources of medical information such
as doctors or it may be examined through experiments. The experiments would
need to be voluntary however, and the user would need to know the possible
risks.
One
of the most difficult and important tasks with a project related to speech
based computer games is to remember the speech interface. It is far too easy to
make a design decision later on in the project that influences the speech
interface. Such an example would be the way in which the enemy players were not
given the ability to fight back in early Wizard of Oz experiments. The process
of suddenly giving the enemy this ability later in the project has meant that
the manner in which bots may work together to combat the strength of the enemy
has not been fully examined. This could have led to the creation of the concept
of squads as in the Quake 3 Arena [5] command line interface. The manner in
which successive iterations of prototyping and wizard of Oz experiments are
performed must be such that only small changes occur between each step. This is
opposed to the method of making large changes between iterations which comes
naturally. The desire to do this occurs because the developer has seen
something interesting which opens up possibilities that the developer wants to
create as soon as possible. Such a distraction occurred on this project when
the tasks which the bots could do were considered. The bots were worked on and
a lot of the internal functions of the game were changed to accommodate this
work. This led to the problem of how the bots would go round corners being a
focal issue for about a month. It was only when it was realised that the bot
being stuck on a corner was a feature which was making the two sides more
equal. Although this happens to both sets of bots, the player’s side may be
ordered in such a way that overcomes this and exploits this in the enemy while
the enemy side does not think that anything is wrong. It is also the case that
the enemies seem to be more effective at rushing into a enclosed space and
shooting everyone so this is why the two sides are more equal.
5.1 Relationships with other projects:
Examining
the grammar for the Quake 3 Arena [5] command line interface, it may seem as if
it would have been a good idea to copy the grammar to use in this game to avoid
Wizard of Oz experiments. Examining the grammar in more detail it can be seen
that the grammar is biased towards American players. This can be seen by the
fact that commands such as “I quit being the leader” and
“<botname> stop action” are quite unlikely constructs to be used in
English sentences. This is one way of advocating the use of Wizard of Oz
experiments in speech based computer games. One question which would be
interesting would be to find out if the spoilers used to get the system grammar
in Marc Cavazza’s project [12] were written by an American or an Englishman.
Another factor which could change the effectiveness of a grammar is related to
the accent that was used. In some languages, the accent does not change with
what is said in that region, but in English, colloquialisms occur which are
words and phrases which are only used in a certain region, and that only have
those meanings in a set region. This could be bad for speech based computer
games because the meaning needs to be set and cannot be ambiguous since it is
hard to create programs to deal with ambiguity.
This
project compares quite well with Steve Lackenby’s [1] dissertation since it has
shown similar facts such as the excitement factor, and the speech processing
delay. Where this project builds on that dissertation is that the amount of
high reaction games not very compatible with the speech interface has
increased, but the definition of high reaction is a changeable concept. It is
this manner in which this game may be possibly slowed down to use more strategy
aspects than high speed action aspects of the game. In this way, a high
reaction game becomes a normal reaction game. This is similar to the player
speeding up to suit the interface in the interface acceptability experiment.
This
project proves some similar issues as were discovered by examining “Hey, you,
Pikachu!” [10]. The player’s enjoyment was seen to drop in the interface
acceptability experiment due to the response of the system being
unsatisfactory. A similar thing was seen in the Pikachu game and the prediction
from this that the user would reduce the use of the interface and try other
means is proved by the experiment.
The
Situated AI project by Marc Cavazza [12] which was discussed earlier is more
interesting after creating the game and examining the pitfalls. The fact that
the project focuses more on the AI and path planning rather than the speech
interface may be because the intention is to make one part of the system better
than the rest. The speech interface may have been considered complete by the people
working on the project, so the prospect of this interface being updated and
tested constantly with the rest of the system might not have been examined as
much as it could have been. A better idea for creating speech controlled bots
for both this project and the dissertation could have been to perform Wizard of
Oz experiments to get the grammar, and then to get the artificial intelligence
that has already been created and use that in the bot implementation. This
would allow the project to focus more on the speech related parts of the
project.
5.2 Possible
improvements to this project:
There
are many improvements that could be made to this project. Some are related to
the speech recognition side of the project while others are related to the bot
and others still are related to the game which was created.
The
speech interface is the most important part of the project which could be
changed. For example, the speech processing delay is currently too large for
the current task. To solve this, the speed of the game could be reduced to make
the game accept the consequences of such a delay. Another method which could be
considered could be having the kill command as the bots default behaviour, and
having the player control the bots to do other things. This would reduce the
amount of commands given to the bots since the ‘kill’ command is used the most.
The
grammar recognition method is also quite weak when compared to the expressive
power of natural language. To solve this, it was be interesting to implement a
dictation recogniser which uses statistical key word detection. Such a
recogniser looking for the key word ‘find’ would be able to detect the word
quite easily. The words around the key word could then be searched to get any
other information that is required to carry out that command. The power of this
method is that a command with the word ‘find’ in it is very likely to be about
finding something or someone. If searching the words around the key word was
not successful, it would be easy for the system to ask the player “Find who?”
or “Find what?”. A brief conversation could take place such as User: “Player 1,
Find.”, Player 1: “Find what?”, User: “A player?”, Player 1: “Find who?”, User:
“Player 2.” Player 1: “Ok.”.
Another
way of getting around the problem that there are many ways to say the same
thing could involve creating a program that can rewrite sentences in many ways
to make them mean the same thing. This program would be like a thesaurus for
sentences. The grammar could then be processed and the various sentences could
be added to the grammar with a tag that shows they all mean the same thing.
The
bots may be improved so that they may have path following abilities as in Marc
Cavazza’s project [12]. This would mean they would be able to comprehend “Kill
Player 2 then Player 3 then Player 4.”, if the Wizard of Oz
experiment claimed they needed to. Other improvements to the bots include the
advanced system for moving around corners as mentioned earlier which only
involves the player deciding if it can move to the player by if it can move to
the player rather than deciding if it can move to a player by considering
whether they can see it or not.
Having
bots which attempt to give orders to the user would be an interesting direction
for this project to take although this has already been implemented in Quake 3
Arena [5]. As a further direction, however, there could be a power struggle
type of situation where one of the bots wants to give orders, gets told off by
the user, and attempts a mutiny with a couple of other bots from the player’s
team.
A
more advanced behaviour that could be added to the bots is that the AI could be
made to have simple emotions, and the characters could actually be able to
panic in the middle of a battle, with lots of friendly fire hurting your own
team, and then it would be the user’s task to reassure this character and calm
it down using dialogue. In a similar way, speech could be used to infuriate the
enemy AI, and to make them either too confident or panicked. To make things more
interesting, the AI characters could be made to talk to and understand and bait
each other, adding an extra dimension to the game. Dealing with detecting and
imitating emotions in computer systems is an interesting field known as
Affective Computing [22].
There
are many features which could enhance the game world that the bots are in. The
first would be to make the world larger so a lot more may happen in it and a
lot more bots can exist and fight in it. This would give the user more variety
than the small arena which exists at the moment. A feature which could be used
in additional research would be to add more interesting objects into the arena
and to see how these are referred to by the players. This complements the
research that the first Wizard of Oz experiments discovered about
distinguishable objects such as a blue wall and a yellow wall. It was
identified that because of their ability as a reference, and the player is able
to order a bot to “go to blue wall” as a result. The more complex and interesting
the objects in the arena are, the more complex and interesting the commands are
to interact with these objects. A banana in a game world may be eaten, thrown,
dropped, placed on a table, and used in many more ways. This requires the
grammar to match the interaction of the banana with the user and the game world
and become more advanced.
The
next improvement that could be made to the game would be for bots to be able to
understand pointing when said with ‘that’ or ‘over there’ as a reference to an
object or some aspect of the environment. This is similar to the method of
multimodality shown in Sharon Oviatt’s paper “10 myths of multimodal systems”
[3]. Such a system creates more problems than it solves because the definition
of ‘over there’ in the phrase ‘go over there’ does not include any information
related to how far ‘over there’ the user requires the player to go. This may be
implemented in such that the bot will position itself at a reasonable distance
away from the user in the direction given. The user would then be able to
change the desired range by asking the player to ‘come closer’ or ‘move further
back’.
The
final and most important improvement that may be made to this project is that
more tests need to be carried out as outlined in section 3. These tests would
prove the worth of the speech interface when compared against other interfaces
and would also test the system thoroughly.
5.3 Advanced
projects:
The
advanced projects are those that it would be interesting to research because of
the results that may be discovered.
As
noted in section 2.7, the command line interface is powerful but is not used
very much because it compromises the safety of the player because the player is
unable to fight back in that mode. If a speech interface was used to input the
appropriate commands, this would allow the player to defend themselves at the
same time as command input. This project would advocate the multimodal use of
speech in a high reaction environment, but the resource drain of the speech
recogniser added with the resource drain of such a demanding game would be
problematic.
As
mentioned in section 2.5, adding speech interaction to the game Half-Life [9]
and giving the bots more realistic features would create a game which allows
the user to interact on more levels than previously. The level of speech input
might be quite basic and controlled by a statistical key word recogniser. Only
adding phrases like “Hello, Barney.” and “I need some help with the <x>.”
would increase the lifelike realism of the game. To go a step further, similar
procedures used in this project to control a group of bots could be used in
Half-Life to control a small group of Special Forces characters. In this case,
it would be like controlling a group of human players since the bots already
have basic human attributes such as sampled speech and intelligent problem
solving and planning abilities.
It
would be interesting if a project was undertaken to examine how many different
speech samples it requires before the player is assumed to be human. This
project would investigate the amount of real objects that may be used
interchangeably to simulate objects with random fluctuations in real life,
which would be useful for creating realistic computer games that immerse the
player in a ‘real’ world.
Chapter 6:
Conclusions
From
investigating what speech is, and what it is commonly used for, it has been
proved possible to create a game that matches the interface in the case of a
speech based computer game where you can command bots using speech.
The
bot in the game has been implemented to be asked information and given orders
to interact in a certain way with the game world and it’s contents. These
orders can then be carried out in the game world by the bot.
This
dissertation has shown that realism in computer games plays a part when it
comes to an immersive world that may be interacted with on many levels and that
bots have to match human player characteristics such as speed and response in
order to be presumed human.
Various
experiments have been created to support the development and testing of the
system and have proved that the user responds to changes and characteristics of
the interface.
The
project has been discussed and compared with various sources and it has been
shown how improvements may be made to this project as well as what other
projects may want to examine as a result of this project.
This
dissertation has also considered what properties make up a speech interface
such as the speech recogniser and the rest of the interface. This has led to
various possible speech interfaces being created.
There
is an example discourse from a Wizard of Oz experiment in the appendix as well
as the current grammar.
References:
[1]: Steve Lackenby. (1998) Speech and Computer Games A Dissertation for the Department of
Computer Science, Sheffield, England.
[2]:
Mark Wrangham. (1999) Speech and Computer
Games A Dissertation for the Department of Computer Science, Sheffield,
England.
[3]:
Sharon Oviatt. 10 myths of multi-modal
interaction. A paper appearing in Communications of the ACM, Vol. 42, No.
11, November, 1999, pp. 74-81/
[4]:
Sun Microsystems. (1997-8) Java Speech
API Programmers Guide. http://java.sun.com
[5]:
ID Software (1999) Quake 3 Arena A PC
game published by Activision.
[6]:
IBM (1999) ViaVoice Millennium A
Speech Recogniser published by IBM.
[7]:
Nintendo (1997) The Legend of Zelda A
N64 game published by Nintendo.
[8]:
Xatrix (1998) Kingpin – Life of Crime
A PC game.
[9]:
Valve Software (1997) Half-Life A PC
game published by Sierra.
[10]:
Nintendo (1999) Hey, you, Pikachu! /
Pikachu Genki Dechu
A
N64 game published by Nintendo.
Resources
used:
Adam
Einhorn (1999) Pikachu Genki Dechu FAQ
Version .3 http://www.gamefaqs.com
Official
site:
[11]:
Vivarium (2000) Seaman A Dreamcast
game published by Sega.
Useful Resources:
Tim
Tilley (2000) The complete guide to Sega
Dreamcast's Seaman Available at:
http://www.gamingplanet.com/console/dreamcast/cheats/walkthoughs/seaman_a.txt
[12]:
Marc Cavazza, Srikanth Bandi and Ian Palmer
(1998) ”Situated AI” in Video
Games: Integrating NLP, Path Planning and 3D Animation.
[13]:
University of Edinburgh (1999) Wizard of
Oz Simulations Available at: http://www.ccir.ed.ac.uk/centre/woz.html
[14]:
Satoshi Konno Joystick Interface for Java
Available to download from the internet at: http://www.cyber.koganei.tokyo.jp/top/index.html
[15]: LucasArts Monkey Island published by LucasArts.
[16]: Sierra Space Quest published by Sierra.
[17]: Westwood Studios (1997) Blade Runner published by Westwood.
[18] SquareSoft (1998) Final Fantasy 7
[19] Radiohead Fitter, Happier. From the album Ok, Computer. By Radiohead.
[20] A. Turing The
Turing Test
[21] L. Frank Baum The Wonderful Wizard of Oz
[22] Rosalind W. Picard (1997) Affective Computing (ISBN 0-262-16170-2)
Appendices:
An
example dialogue for the Wizard of Oz experiment:
<user
is told to interact with his super intelligent ‘personal assistant’>
User:
Do I call him player B?
<user
is told to call it whatever he likes>
User:
I don’t know, B might be simpler..
User:
So.. B..
Wizard:
Yes.
User:
Ah! He answered!
User:
Um, B. Move to gray wall.
<wizard
moves>
<user
laughs>
User:
Stop.
Wizard:
Absolutely.
User:
Um, player D is at 2 o’clock.
User:
Shoot player D.
Wizard:
Ok.
User:
yay!
<Player
D gets shot>
<Player
D hides from player B>
User:
Shoot player D.
<user
laughs>
<Player
D gets shot by user and Player B>
<Player
B gets shot by user>
User:
Oops.
User:
Move to gray wall.
Wizard:
I’m not smart enough. (Accidental
button press)
<user
confusion>
<Player
B moves to gray wall>
User:
Follow me.
<player
B follows user>
User:
Fantastic!
User:
Move faster.
Wizard:
I don’t get it.
User:
Walk faster.
Wizard:
What are you saying?
User:
March.
<user
clicks with disapproval>
Wizard:
What?
<user
has decided to confuse the wizard again>
User:
Porn?
<The
input of this symbol is valid, but would not be in the grammar, so the best
response was to get the user to say something else.>
Wizard:
I don’t understand.
<user
is bored>
<wizard
hasn’t been told anything to do for a while and gets impatient.>
Wizard:
Yes?
User:
Move to pink wall no purple wall.
User:
Go to purple wall.
<wizard
on its way>
User:
Player G at two o’clock.
Wizard:
Absolutely. (after unnatural pause.)
<user
sighs, showing disappointment>
User:
Face me.
<User
has lost the plot, unknown to the wizard>
Wizard:
Absolutely.
User:
So I can kill you!
<Wizard
doesn’t stand a chance>
Wizard:
I’m not smart enough.
User:
Obviously not, you’re dead.
<user
laughs evilly>
The
final grammar of the System:
grammar
javax.speech.demo;
public
<command> = (computer end program | stop program) {bye} |
<order>
[<urgency>]|
<order>
[<urgency>] <name> {orderedto} |
<name>
{orderedto} <order> [<urgency>]|
<name>
{orderedto} <query>|
<query>
<name> {orderedto} |
(yes
| positive | absolutely) {yes}|
(no
| don't | no way) {no};
<query>
= what are you doing {qdoing} |
where
are you going {qgoing} |
who
are you (chasing | seeking | finding | killing | locating) {qchasing} |
where
are you {qwhere} |
how
am I {qhowami} |
how
are you {qhow} |
what
is the score {qscore} |
how
much health do you have {qhealth};
<order>
= (hunt | locate | chase | find | follow) {locate} <name> |
(avoid
| run away from) {avoid} <name> |
run
{avoid} away {0} |
check
{check} my <clock> |
patrol
{patrol}|
(attack
| kill | shoot) {attack} <name> |
((enemy
| bandit) {0} | <name>) [is] at {at} <clock> |
run
away {avoid} [from <name>] |
avoid
{avoid} [<name>] |
(help
| assist | protect) {help} <name> |
go
[to] {go} <object> |
come
{go} here {here} |
sing
for me {sing} |
(stop
| don't do that | wait) {stop} |
(continue
| proceed | carry on) {proceed};
<urgency>
= immediately | straight away | [right] now;
<object>
= <wallName> wall | there {there};
<wallName>
= blue {5} |
((light
| pale) blue | cyan) {6} |
[light]
grey {7} |
green
{8} |
(magenta
| purple) {9} |
(orange
| yellow) {10} |
pink
{11} |
red
{12} |
north
{1}|
south
{3}|
west
{2}|
east
{4};
<name>
= (me | <playernames1> | [player] 1) {1} |
(<playernames2>|
[player] 2) {2} |
(<playernames3>
| [player] 3) {3} |
(<playernames4>
| [player] 4) {4} |
(<playernames5>
| [player] 5) {5} |
(<playernames6>
| [player] 6) {6};
<playernames1>
= steve;
<playernames2>
= andy;
<playernames3>
= dunk;
<playernames4>
= bob;
<playernames5>
= bill;
<playernames6>
= der;
<clock>
= (1 {1}| 2 {2}| 3 {3}| 4 {4}| 5 {5}| 6 {6}| 7 {7}| 8 {8}| 9 {9}| 10 {10}| 11
{11}| 12 {12}) [o clock];